Optimization Nuggets: Stochastic Polyak Step-size
A simple step-size tuner with optimal rates
The stochastic Polyak step-size (SPS) is a practical variant of the Polyak step-size for stochastic optimization. In this blog post, we'll discuss the algorithm and provide a simple analysis for convex objectives with bounded gradients.
$$ \require{mathtools} \require{color} \def\aa{\boldsymbol a} \def\rr{\boldsymbol r} \def\AA{\boldsymbol A} \def\HH{\boldsymbol H} \def\EE{\mathbb E} \def\II{\boldsymbol I} \def\CC{\boldsymbol C} \def\DD{\boldsymbol D} \def\KK{\boldsymbol K} \def\eeps{\boldsymbol \varepsilon} \def\tr{\text{tr}} \def\LLambda{\boldsymbol \Lambda} \def\bb{\boldsymbol b} \def\cc{\boldsymbol c} \def\xx{\boldsymbol x} \def\zz{\boldsymbol z} \def\uu{\boldsymbol u} \def\vv{\boldsymbol v} \def\qq{\boldsymbol q} \def\yy{\boldsymbol y} \def\ss{\boldsymbol s} \def\pp{\boldsymbol p} \def\lmax{L} \def\lmin{\ell} \def\RR{\mathbb{R}} \def\TT{\boldsymbol T} \def\QQ{\boldsymbol Q} \def\CC{\boldsymbol C} \def\Econd{\boldsymbol E} \DeclareMathOperator*{\argmin}{{arg\,min}} \DeclareMathOperator*{\argmax}{{arg\,max}} \DeclareMathOperator*{\minimize}{{minimize}} \DeclareMathOperator*{\dom}{\mathbf{dom}} \DeclareMathOperator*{\Fix}{\mathbf{Fix}} \DeclareMathOperator{\prox}{\mathbf{prox}} \DeclareMathOperator{\span}{\mathbf{span}} \def\defas{\stackrel{\text{def}}{=}} \def\dif{\mathop{}\!\mathrm{d}} \definecolor{colormomentum}{RGB}{27, 158, 119} \def\cvx{{\color{colormomentum}\mu}} \definecolor{colorstepsize}{RGB}{217,95,2} \def\stepsize{{\color{colorstepsize}{\boldsymbol{\gamma}}}} \def\harmonic{{\color{colorstep2}\boldsymbol{h}}} \def\cvx{{\color{colorcvx}\boldsymbol{\mu}}} \def\smooth{{\color{colorsmooth}\boldsymbol{L}}} \def\noise{{\color{colornoise}\boldsymbol{\sigma}}} \definecolor{color1}{RGB}{127,201,127} \definecolor{color2}{RGB}{179,226,205} \definecolor{color3}{RGB}{253,205,172} \definecolor{color4}{RGB}{203,213,232} $$SGD with Polyak Step-size
A recent optimization breakthrough result is the realization that the venerable Polyak step-size,
Let $f$ be an average of $n$ functions $f_1, \ldots, f_n$, and we consider the problem of finding a minimizer of $f$: \begin{equation}\label{eq:opt} x_{\star} \in \argmin_{x \in \RR^p} \left\{ f(x) \defas \frac{1}{n} \sum_{i=1}^n f_i(x) \right\}\,, \end{equation} with access to subgradients of $f_i$. In this post we won't be assuming smoothness of $f_i$, so this subgradient is not necessarily unique. To avoid the notational clutter from having to deal with sets of subgradients, we take the convention that $\nabla f_i(x)$ denotes any subgradient of $f_i(x)$.
There have been by now a few formulations of this method, with subtle differences. The variant that I present here corresponds to what Garrigos et al. 2023 call the $\text{SPS}_+$ method. Unlike the earlier variants of Berrada et al. 2020 and Loizou et al. 2021, this variant doesn't have a maximum step-size.
SGD with Stochastic Polyak Step-size (SGD-SPS)
Input: starting guess $x_0 \in \RR^d$.
For $t=0, 1, \ldots$
\begin{equation}\label{eq:sps}
\begin{aligned}
& \text{sample uniformly at random } i \in \{1, \ldots, n\}\\
& \stepsize_t = \frac{1}{\|\nabla f_i(x_t)\|^2}(f_i(x_t) - f_i(x_\star))_+ \\
&x_{t+1} = x_t - \stepsize_t \nabla f_i(x_t)
\end{aligned}
\end{equation}
In the algorithm above, $(z)_+ \defas \max\{z, 0\}$ denotes the positive part function, and $\frac{1}{\|\nabla f_i(x_t)\|^2}$ should be understood as the pseudoinverse of $\|\nabla f_i(x_t)\|^2$ so that the step-size is zero whenever $\|\nabla f_i(x_t)\| = 0$.
This step-size $\stepsize_t$ is a marvel of simplicity and efficiency. The denominator $\|\nabla f_i(x_t)\|^2$ is the squared norm of the partial gradient, which we anyway need to compute for the update direction. The numerator depends on the partial function value $f_i(x_t)$, which in most automatic differentiation frameworks can be obtained for free as a by-product of the gradient. All in all, the overhead of the stochastic Polyak step-size is negligible compared to the cost of computing the partial gradient.
Not everything is rainbows and unicorns though.
The Polyak step-size has one big drawback. It requires knowledge of the partial function at the minimizer, $f_i(x_\star)$.
Convergence under Star Convexity and Locally Bounded Gradients
We'll now prove that the SGD-SPS algorithm enjoys a $\mathcal{O}(1/\sqrt{t})$ convergence rate for star-convex objectives with bounded gradients (optimal for this class of functions!).
The two assumptions that we will make on the objective are star-convexity
A function $f_i$ is star-convex around $x_\star$
Convex functions are star-convex, since they verify \eqref{eq:star-convexity} for all pairs of points $x, x_\star$, while in the definition above $x_\star$ is fixed. The converse is not true, and star-convex functions can have non-convex level sets (for example star-shaped).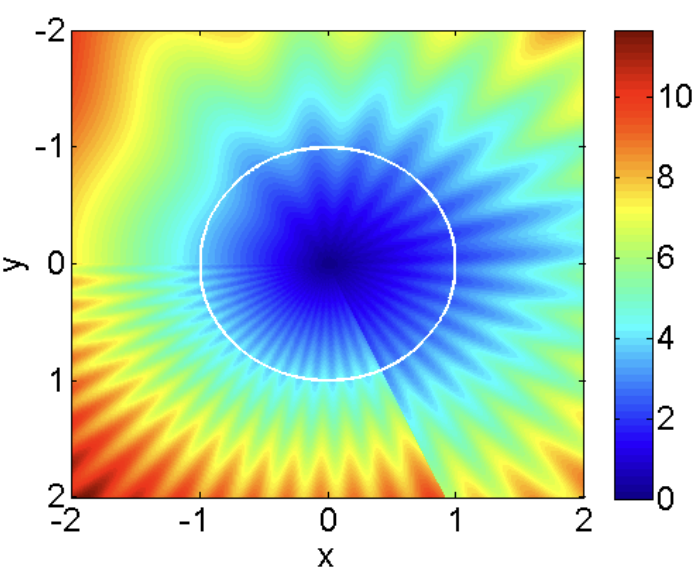
Heatmap of a function that is star-convex but not convex. Credits: (Lee and Valiant, 2016).
The other assumption that we'll make is that the gradients $\nabla f_i$ are locally bounded. This assumption is satisfied by many objectives of interest, including least-squares and logistic regression. With this, here is the main result of this post.
Assume that for all $i$, $f_i$ is star-convex around a minimizer $x_\star$. Furthermore, we'll also assume that the subgradients are bounded in the ball $\mathcal{B}$ with center $x_\star$ and radius $\|x_0 - x_\star\|$, that is, we have $\|\nabla f_i(x)\|\leq G$ for all $i$ and $x \in \mathcal{B}$. Then, SGD-SPS converges in expected function error at a rate of at least $O(1/\sqrt{T})$. That is, after $T$ steps we have \begin{equation} \min_{t=0, \ldots, T-1} \,\EE f(x_t) - f(x_\star) \leq \frac{G}{\sqrt{T}}\|x_0 - x_\star\| \,. \end{equation}
The proof mostly follows that of Garrigos et al. 2023,
I've structured the proof into three parts. 1️⃣ first we'll establish that the iterates are bounded. This will allow us to avoid making a global Lipschitz assumption. 2️⃣ then we'll derive a key inequality that relates the error at two subsequent iterations. In 3️⃣ we'll sum this inequality over iterations, some terms will cancel out, and we'll get the desired convergence rate.
1️⃣ Error is monotonically decreasing. We'd like to show that the iterate error $\|x_t - x_\star\|^2$ is monotonically decreasing in $t$. Let's consider first the case $\|\nabla f_i(x_t)\| \neq 0$, where $i$ denotes the random index selected at iteration $t$. Then using the definition of $x_{t+1}$ and expanding the square we have \begin{align} &\|x_{t+1} - x_\star\|^2 = \|x_t - x_\star\|^2 - 2 \stepsize_t \langle \nabla f_i(x_t), x_t - x_\star\rangle + \stepsize_t^2 \|\nabla f_i(x_t)\|^2 \nonumber\\ &\quad\stackrel{\text{(star convexity)}}{\leq} \|x_t - x_\star\|^2 - 2 \stepsize_t (f_i(x_t) - f_i(x_\star)) + \stepsize_t^2 \|\nabla f_i(x_t)\|^2 \nonumber\\ &\quad\stackrel{\text{(definition of $\stepsize_t$)}}{=} \|x_t - x_\star\|^2 - \frac{(f_i(x_t) - f_i(x_\star))_+^2}{\|\nabla f_i(x_t)\|^2} \label{eq:last_decreasing} \end{align} This last equation shows that the error is monotonically decreasing whenever $\|\nabla f_i(x_t)\| \neq 0$.
Let's now consider the case $\|\nabla f_i(x_t)\| = 0$. In this case, the step-size is 0 by our definition of $\stepsize_t$, and so the error is constant. We have established that the error is monotonically decreasing in both cases.
2️⃣ Key recursive inequality. Let's again first consider the case $\|\nabla f_i(x_t)\| \neq 0$. Since we've established that the error is monotonically decreasing, the iterates remain in the ball centered at $x_\star$ with radius $\|x_0 - x_\star\|$. We can then use the locally bounded gradients assumption on \eqref{eq:last_decreasing} to obtain \begin{equation}\label{eq:recursive_G} \|x_{t+1} - x_\star\|^2 \leq \|x_t - x_\star\|^2 - \frac{1}{G^2}(f_i(x_t) - f_i(x_\star))_+^2 \,. \end{equation}
Let's now consider the case in which $\|\nabla f_i(x_t)\| = 0$. In this case, because of star-convexity, we have $f_i(x_t) - f_i(x_\star) \leq 0$ and so $(f_i(x_t) - f_i(x_\star))_+ = 0$. Hence inequality \eqref{eq:recursive_G} is also trivially verified. We have established that \eqref{eq:recursive_G} holds in all cases.
Let $\EE_t$ denote the expectation conditioned on all randomness up to iteration $t$. Then taking expectations on both sides of the previous inequality and using Jensen's inequality on the convex function $z \mapsto z^2_{+}$ we have \begin{align} \EE_t\|x_{t+1} - x_\star\|^2 &\leq \|x_t - x_\star\|^2 - \frac{1}{G^2} \EE_t(f_i(x_t) - f_i(x_\star))_+^2 \\ &\stackrel{\mathclap{\text{(Jensen's)}}}{\leq} \|x_t - x_\star\|^2 - \frac{1}{G^2} (f(x_t) - f(x_\star))^2 \,, \end{align} where we have dropped the positive part in the last term, which is non-negative by definition of $x_\star$. Finally, taking full expectations on both sides, using the tower property of expectation and rearranging we have our key recursive inequality: \begin{equation}\label{eq:key_inequality} \boxed{\vphantom{\sum_a^b} \EE(f(x_t) - f(x_\star))^2 \leq G^2(\EE\|x_t - x_\star\|^2 - \EE\|x_{t+1} - x_\star\|^2)} \end{equation}
3️⃣ Telescoping and final rate. Using Jensen's inequality once more, we have \begin{align} \min_{t=0, \ldots, T-1}\,(\EE f(x_t) - f(x_\star))^2~&\stackrel{\mathclap{\text{(Jensen's)}}}{\leq}~\min_{t=0, \ldots, T-1} \EE(f(x_t) - f(x_\star))^2\\ &\leq \frac{1}{T}\sum_{t=0}^{T-1} \EE(f(x_t) - f(x_\star))^2 \\ &\stackrel{\eqref{eq:key_inequality}}{\leq} \frac{G^2}{T} \|x_0 - x_\star\|^2 \end{align} Taking square roots on both sides gives \begin{equation} \sqrt{\min_{t=0, \ldots, T-1}\,(\EE f(x_t) - f(x_\star))^2} \leq \frac{G}{\sqrt{T}} \|x_0 - x_\star\|\,. \end{equation} Finally, by the monotonicity of the square root, we can bring the square root inside the $\min$ to obtain the desired result.
Citing
If you find this blog post useful, please consider citing as
Stochastic Polyak Step-size, a simple step-size tuner with optimal rates, Fabian Pedregosa, 2023
with bibtex entry:
@misc{pedregosa2023sps,
title={Stochastic Polyak Step-size, a simple step-size tuner with optimal rates},
author={Fabian Pedregosa},
howpublished = {\url{http://fa.bianp.net/blog/2023/sps/}},
year={2023}
}
Acknowledgments
Thanks to Robert Gower for first bringing this proof to my attention, and then for answering all my questions about it. Thanks also to Vincent Roulet for proof reading this post and making many useful suggestions.