Abstract: We propose and analyze a novel adaptive step size variant of the Davis-Yin three operator splitting, a method that can solve optimization problems composed of a sum of a smooth term for which we have access to its gradient and an arbitrary number of potentially non-smooth terms for which we have access to their proximal operator. The proposed method leverages local information of the objective function, allowing for larger step sizes while preserving the convergence properties of the original method. It only requires two extra function evaluations per iteration and does not depend on any step size hyperparameter besides an initial estimate. We provide a convergence rate analysis of this method, showing sublinear convergence rate for general convex functions and linear convergence under stronger assumptions, matching the best known rates of its non adaptive variant. Finally, an empirical comparison with related methods on 6 different problems illustrates the computational advantage of the adaptive step size strategy.
We propose a step-size for the Frank-Wolfe and Matching Pursuit algorithms that only depends on local information of the objective. This allows to take larger step-sizes and converge faster.
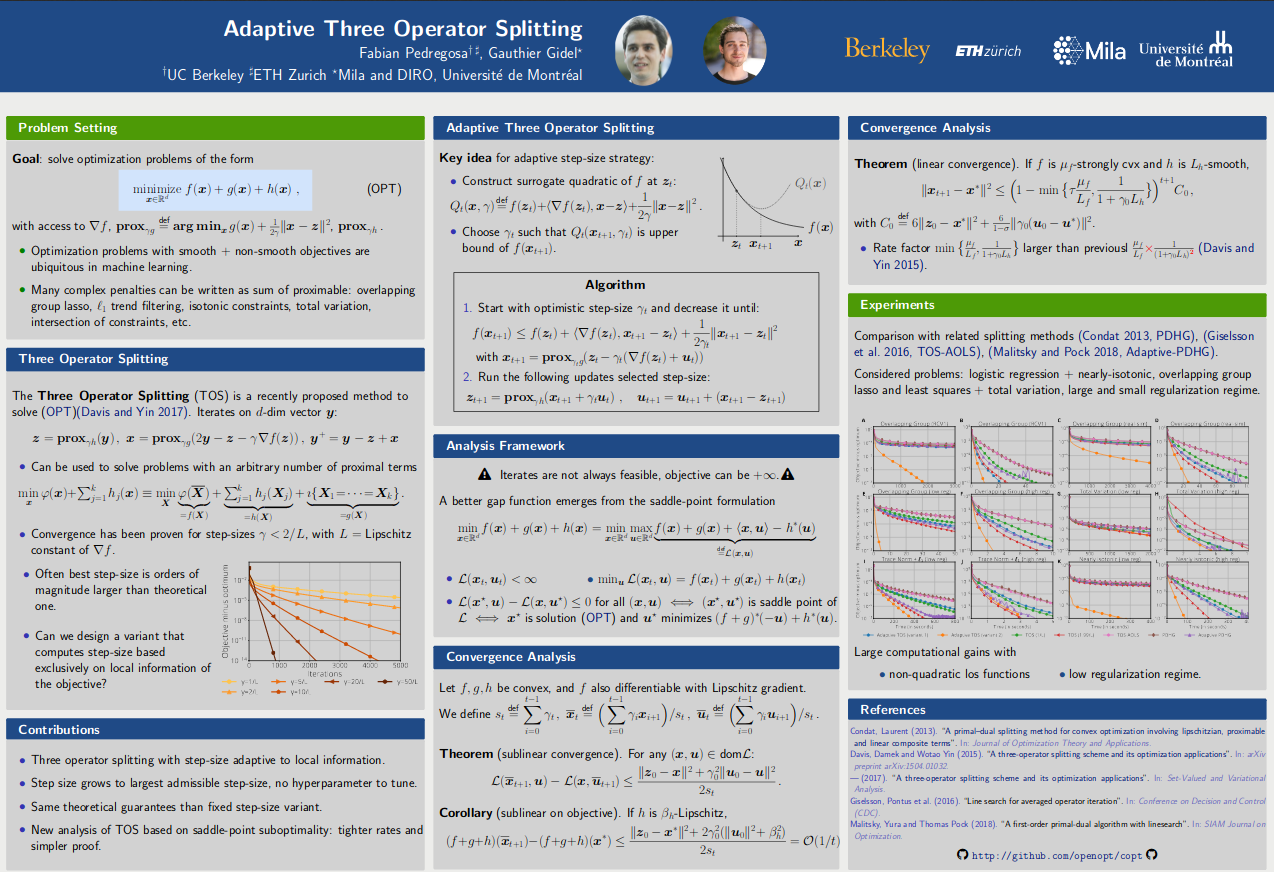
Abstract: Minimizing a function over an intersection of convex sets is an important task in optimization that is often much more challenging than minimizing it over each individual constraint set. While traditional methods such as Frank-Wolfe (FW) or proximal gradient descent assume access to a linear or quadratic oracle on the intersection, splitting techniques take advantage of the structure of each sets, and only require access to the oracle on the individual constraints. In this work, we develop and analyze the Frank-Wolfe Augmented Lagrangian (FW-AL) algorithm, a method for minimizing a smooth function over convex compact sets related by a “linear consistency” constraint that only requires access to a linear minimization oracle over the individual constraints. It is based on the Augmented Lagrangian Method (ALM), also known as Method of Multipliers, but unlike most existing splitting methods, it only requires access to linear (instead of quadratic) minimization oracles. We use recent advances in the analysis of Frank-Wolfe and the alternating direction method of multipliers algorithms to prove a sublinear convergence rate for FW-AL over general convex compact sets and a linear convergence rate for polytopes.
The Randomized Away-steps FW variant that we propose (RAFW) is competitive with Away-steps FW (AFW), albeit with a much smaller per iteration cost.
Frank-Wolfe with Subsampling Oracle, Thomas Kerdreux, Fabian Pedregosa, Alexandre d'Aspremont, Proceedings of the 35th International Conference on Machine Learning, 2018. ICML, ArXiv
Abstract: We analyze two novel randomized variants of the Frank-Wolfe (FW) or conditional gradient algorithm. While classical FW algorithms require solving a linear minimization problem over the domain at each iteration, the proposed method only requires to solve a linear minimization problem over a small subset of the original domain. The first algorithm that we propose is a randomized variant of the original FW algorithm and achieves a (1/t) sublinear convergence rate as in the deterministic counterpart. The second algorithm is a randomized variant of the Away-step FW algorithm, and again as its deterministic counterpart, reaches linear (i.e., exponential) convergence rate making it the first provably convergent randomized variant of Away-step FW. In both cases, while subsampling reduces the convergence rate by a constant factor, the linear minimization step can be a fraction of the cost of that of the deterministic versions, especially when the data is streamed. We illustrate computational gains of the algorithms on regression problems, involving both L1 and latent group lasso penalties .
Abstract: As datasets continue to increase in size and multi-core computer architectures are developed, asynchronous parallel optimization algorithms become more and more essential to the field of Machine Learning. Through a novel perspective, we revisit and clarify a subtle but important technical issue present in a large fraction of the recent convergence rate proofs for asynchronous parallel optimization algorithms, and propose a simplification of the recently introduced "perturbed iterate" framework that resolves it. We demonstrate the usefulness of our new framework by analyzing three distinct asynchronous parallel incremental optimization algorithms: Hogwild (asynchronous SGD), KROMAGNON (asynchronous SVRG) and ASAGA, a novel asynchronous parallel version of the incremental gradient algorithm SAGA that enjoys fast linear convergence rates.
Abstract: We propose and analyze adaptive step-size (also known as inexact line search) variants of different projection-free algorithms such as Frank-Wolfe, its Away-Steps and Pairwise variants as well as Matching Pursuit. The proposed methods leverage local information of the objective through a backtracking line search strategy. This has two key advantages: First, it does not require to estimate constants of the objective that might be costly to compute, such as the Lipschitz or the curvature constant. Second, the proposed criterion is adaptive to local information of the objective, allowing for larger step-sizes. For all proposed methods, we derive convergence rates on convex and non-convex problems that asymptotically match the strongest known bounds for non-adaptive variants. As a side-product of our analysis we obtain the first known bounds for matching pursuit on non-convex objectives. Benchmarks on three different datasets illustrate the practical advantages of the method.
Abstract: Despite the rise to fame of incremental variance-reduced methods in recent years, their use in nonsmooth optimization is still limited to few simple cases. This is due to the fact that existing methods require to evaluate the proximity operator for the nonsmooth terms, which can be a costly operation for complex penalties. In this work we introduce two variance-reduced incremental methods based on SAGA and SVRG that can efficiently take into account complex penalties which can be expressed as a sum of proximal terms. This includes penalties such as total variation, group lasso with overlap and trend filtering, to name a few. Furthermore, we also develop sparse variants of the proposed algorithms which can take advantage of sparsity in the input data. Like other incremental methods, it only requires to evaluate the gradient of a single sample per iteration, and so is ideally suited for large scale applications. We provide a convergence rate analysis for the proposed methods and show that they converge with a fixed step-size, achieving in some cases the same asymptotic rate as their full gradient variants. Empirical benchmarks on 3 different datasets illustrate the practical advantages of the proposed methods.
Teaser video of the paper "Breaking the Nonsmooth Barrier: A Scalable Parallel Method for Composite Optimization" (youtube link)
 In the proposed method, the candidate step size must verify a sufficient decrease condition, which can be interpreted as a quadratic upper bound on the objective function.
Adaptive Three Operator Splitting, Fabian Pedregosa, Gauthier Gidel, Proceedings of the 35th International Conference on Machine Learning, 2018. ICML, ArXiv, Slides, Poster, Video (starts minute 52).
In the proposed method, the candidate step size must verify a sufficient decrease condition, which can be interpreted as a quadratic upper bound on the objective function.
Adaptive Three Operator Splitting, Fabian Pedregosa, Gauthier Gidel, Proceedings of the 35th International Conference on Machine Learning, 2018. ICML, ArXiv, Slides, Poster, Video (starts minute 52).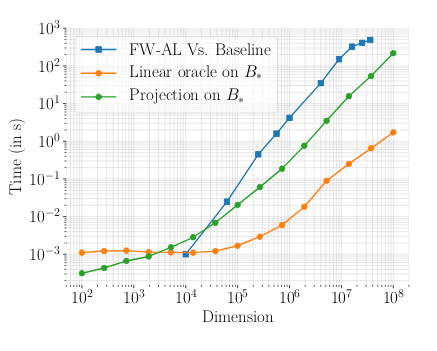 We propose a step-size for the Frank-Wolfe and Matching Pursuit algorithms that only depends on local information of the objective. This allows to take larger step-sizes and converge faster.
We propose a step-size for the Frank-Wolfe and Matching Pursuit algorithms that only depends on local information of the objective. This allows to take larger step-sizes and converge faster.
 The Randomized Away-steps FW variant that we propose (RAFW) is competitive with Away-steps FW (AFW), albeit with a much smaller per iteration cost.
The Randomized Away-steps FW variant that we propose (RAFW) is competitive with Away-steps FW (AFW), albeit with a much smaller per iteration cost.
 In this paper we highlight an issue present in large part of the literature of asynchronous stochastic optimization: under the traditional labeling scheme (i.e., how the iterates are named), gradient estimates might be biased. We propose a solution to this issue via a different labeling scheme.
In this paper we highlight an issue present in large part of the literature of asynchronous stochastic optimization: under the traditional labeling scheme (i.e., how the iterates are named), gradient estimates might be biased. We propose a solution to this issue via a different labeling scheme.
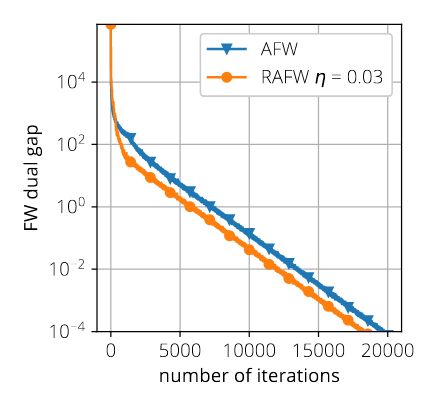
 The Frank-Wolfe variant that we propose (Adaptive FW) only depends on local information of the objective. This allows to take larger step-sizes and converge faster.
The Frank-Wolfe variant that we propose (Adaptive FW) only depends on local information of the objective. This allows to take larger step-sizes and converge faster.