Notes on the Frank-Wolfe Algorithm, Part I
This blog post is the first in a series discussing different theoretical and practical aspects of the Frank-Wolfe algorithm.
Outline:
The Frank-Wolfe Algorithm
Example: using Frank-Wolfe to solve a Lasso problem
Convergence Theory
The Frank-Wolfe Algorithm
The Frank-Wolfe (FW)Originally published as Frank, Marguerite, and Philip Wolfe. "An algorithm for quadratic programming." Naval Research Logistics (1956). See also Jaggi, Martin. "Revisiting Frank-Wolfe: Projection-Free Sparse Convex Optimization." ICML 2013 for a more recent exposition. or conditional gradient algorithm is one of the oldest methods for nonlinear constrained optimization and has seen an impressive revival in recent years due to its low memory requirement and projection-free iterations. It can solve problems of the form
\begin{equation}\label{eq:fw_objective} \minimize_{\boldsymbol{x} \in \mathcal{C}} f(\boldsymbol{x}) ~, \end{equation}
where $f$ is differentiable with $L$-Lipschitz gradientThis is a very standard assumption in optimization, which can be intuitively interpreted as that the objective function must be "smooth", i.e., cannot have any kinks or discontinuities. and the domain $\mathcal{C}$ is a convex and compact set. A convex set is one for which any segment between two points lies within the set. While the FW algorithm does not require the objective function $f$ to be convex, it does require the domain to be a convex set.
A convex set is one for which any segment between two points lies within the set. While the FW algorithm does not require the objective function $f$ to be convex, it does require the domain to be a convex set.
Frank-Wolfe is a remarkably simple algorithm that given an initial guess $\boldsymbol{x}_0$ constructs a sequence of estimates $\boldsymbol{x}_1, \boldsymbol{x}_2, \ldots$ that converges towards a solution of the optimization problem. The algorithm is defined as follows:
\begin{align} &\textbf{Input}: \text{initial guess $\xx_0$, tolerance $\delta > 0$}\nonumber\\ & \textbf{For }t=0, 1, \ldots \textbf{ do } \\ &\quad\boldsymbol{s}_t \in \argmax_{\boldsymbol{s} \in \mathcal{C}} \langle -\nabla f(\boldsymbol{x}_t), \boldsymbol{s}\rangle\label{eq:lmo}\\ &\quad \boldsymbol{d}_t = \ss_t - \xx_t\\ &\quad g_t = \langle - \nabla f(\xx_t), \dd_t \rangle\\ &\quad \textbf{If } g_t < \delta: \\ &\quad\qquad\hfill\text{// exit if gap is below tolerance }\nonumber\\ &\quad\qquad\textbf{return } \xx_t\\ &\quad {\textbf{Variant 1}}: \text{set step size as} \nonumber\\ &\quad\qquad\gamma_t = \vphantom{\sum_i}\min\Big\{\frac{g_t}{L\|\dd_t\|^2}, 1 \Big\}\label{eq:step_size}\\ &\quad \textbf{Variant 2}: \text{set step size by line search}\nonumber\\ &\quad\qquad\gamma_t = \argmin_{\gamma \in [0, 1]} f(\xx_t + \gamma \boldsymbol{d}_t)\label{eq:line_search}\\ &\quad\boldsymbol{x}_{t+1} = \boldsymbol{x}_t + \gamma_t \boldsymbol{d}_t~.\label{eq:update_rule}\\ &\textbf{end For loop}\\ & \textbf{return } \xx_t \end{align}
Contrary to other constrained optimization algorithms like projected gradient descent, the Frank-Wolfe algorithm does not require access to a projection, hence why it is sometimes referred to as a projection-free algorithm. It instead relies on a routine that solves a linear problem over the domain (Eq. \eqref{eq:lmo}). This routine is commonly referred to as a linear minimization oracle.We defined it as a maximization to emphasize its intuitive meaning as the element that correlates the most with the steepest descent (the negative gradient). The names comes from the fact that other references define it equivalently as the minimization $$\boldsymbol{s}_t \in \argmin_{\boldsymbol{s} \in \mathcal{C}} \langle \nabla f(\boldsymbol{x}_t), \boldsymbol{s}\rangle~.$$
The rest of the algorithm mostly concerns finding the appropriate step size to move in the direction dictated by the linear minimization oracle $\dd_t = \ss_t - \xx_t$, where $\ss_t$ is the result of the linear minimization oracle. Among the many different step size rules that the FW algorithm admits, we detail two as Variant 1 and Variant 2. The first variant is easy to compute and only relies on knowledge of (a lower bound on) the Lipschitz constant $L$. The second variant instead allows to make more progress but requires to solve a 1-dimensional problem at each iteration. In some cases, such as when $f$ is a least squares loss and $\mathcal{C}$ is the $\ell_1$ norm ball, the step size selection problem has a closed form optimal solution, in which case this approach (Variant 2) should be preferred. However, in the general case this does not have a closed form solution, in which case the first variant should be preferred.
Image adapted from Gabriel Peyre, (code).
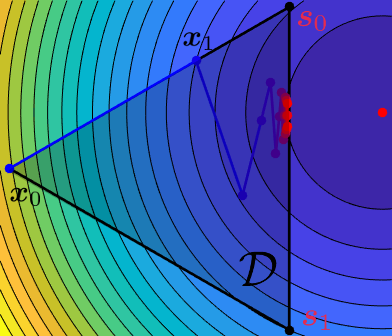
One can see the Frank-Wolfe algorithm is as an algorithm that solves a potentially non-linear problem by solving a sequence of linear ones. The effectiveness of this approach is then tightly linked to the ability to quickly solve the linear subproblems. As it turns out, for a large class of problems, of which the $\ell_1$ or nuclear (also known as trace) norm ball are the most widely known examples, the linear subproblems have either a closed form solution or efficient algorithms exist.For an extensive discussion of the cost the linear minimization oracle, see Jaggi, Martin. "Revisiting Frank-Wolfe: Projection-Free Sparse Convex Optimization." ICML 2013. Compared to a projection, the use of a linear minimization oracle has other important consequences. For example, the output of this linear minimization oracle is always a vertex of the domainBy the properties of linear programs, the optimum value is aways attained on the boundary. and so by the update rule \eqref{eq:update_rule} the iterate is expressed as a convex combination of vertices. This feature can be very advantageous in situations with a huge or even infinite number of features, such as architecture optimization in neural networksPing W, Liu Q, Ihler AT. "Learning infinite RBMs with Frank-Wolfe", Advances in Neural Information Processing Systems (2016). or estimation of an infinite-dimensional sparse matrix arising in multi-output polynomial network.Blondel M, Niculae V, Otsuka T, Ueda N. "Multi-output Polynomial Networks and Factorization Machines", Advances in Neural Information Processing Systems 2017.
There are other step size strategies that I did not mention. For example, the step size can also be set as $\gamma_t = 2/(t+2)$. This is an "oblivious" step size, in that it doesn't depend on any quantity arising from the optimization. As such, it does not perform competitively in practice with the other step size strategies, although it does achieve the same theoretical rate of convergence. Another option, developed by Demyanov and RubinovDemyanov, Vladimir and Rubinov, Aleksandr "Approximate Methods in Optimization Problems". Elsevier (1970). This is an excellent book, but unfortunately it is impossible to find online. and similar to Variant 1 is \begin{equation} \gamma_t = \min\Big\{\frac{g_t}{L\,\diam(\mathcal{C})^2}, 1 \Big\}~,\label{eq:step_size_diam} \end{equation} where $\diam$ denotes the diameter with respect to the euclidean norm.It is possible to use a non-euclidean norm too, as long as the Lipschitz constant $L$ is computed with respect to the same norm. For simplicity we will stick to the euclidean norm. However, since we always have $\|\xx_t - \ss_t\|^2 \leq \diam(\mathcal{C})^2$ by definition of diameter, the step sizes provided by this variant are always smaller than those of Variant 1 and gives a worse empirical convergence. A further improved on this step size consists in replacing the Lipschitz constant $L$ by a local estimate that can potentially be much smaller, allowing for larger step sizes. This approached is developed in our recent paper. Pedregosa, Fabian and Askari, Armin and Negiar, Geoffrey and Jaggi, Martin (2018) "Step-Size Adaptivity in Projection-Free Optimization". arXiv:1806.05123
Yet another step size strategy that has been proposed is based on the notion of curvature constant. The curvature constant $C_f$ is defined as \begin{equation} C_f = \sup_{\substack{\xx,\ss\in\mathcal{C},\gamma\in [0,1] \\ \yy=\xx+\gamma (\ss-\xx)}} \frac{2}{\gamma^2}(f(\yy) - f(\xx) - \langle \yy - \xx, \nabla f(\xx)\rangle) \end{equation} The curvature constant is closely related to our Lipschitz assumption on the gradient. In particular, by the definition above we always have $C_f \leq \diam(\mathcal{C})^2 L$, which given \eqref{eq:step_size_diam} suggests the following rule for the step size: \begin{equation} \gamma_t = \min\Big\{\frac{g_t}{C_f}, 1 \Big\}~.\label{eq:step_size_curvature} \end{equation} This step size was used for example by Lacoste-Julien 2016.Lacoste-Julien, Simon. "Convergence rate of Frank-Wolfe for non-convex objectives." arXiv preprint arXiv:1607.00345 (2016). Note that all the results in this post are in terms of the Lipschitz constant $L$ but analogous results exist in terms of this curvature constant. The obtained rates using this curvature constant are typically tighter, however, they lead to less practical step sizes, since this constant is rarely known in practice.
Example: using Frank-Wolfe to solve a Lasso problem
Some aspects of the algorithm will become clearer with a concrete example. Lets consider a least squares problem with an $\ell_1$ constraint, a problem known as the Lasso. Given a data matrix $\boldsymbol{A} \in \RR^{n \times p}$, a target variable $\boldsymbol{b} \in \RR^n$, and a regularization parameter $\alpha$, this is a problem of the form \eqref{eq:fw_objective} with
\begin{equation}
f(\xx) = \frac{1}{2}\|\boldsymbol{A}\xx - \boldsymbol{b}\|^2~,\quad \mathcal{C} = \{\xx : \|\xx\|_1\leq \alpha\}
\end{equation}
In this case, the domain is a polytope and its vertices are $\{\alpha e_1, -\alpha e_1, \alpha e_2, -\alpha e_2, \ldots, \alpha e_p, -\alpha e_p\}$,
where $e_i$ is the $i$-th element of the canonical basis, i.e., the vector that is zero everywhere except in the $i$-th coordinate, in which it equals one.In a 2-dimensional space, the $\ell_1$ ball of radius $\alpha$ is the convex hull of its 4 vertices $\{\alpha e_1, -\alpha e_1, \alpha e_2, -\alpha e_2\}$, where $e_1 = (1, 0)$ and $e_2 = (0, 1)$ 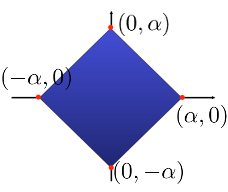 Similarly, in a $p$-dimensional space, the $\ell_1$ ball is the convex hull of $\{\alpha e_1, -\alpha e_1, \alpha e_2, -\alpha e_2, \ldots, \alpha e_p, -\alpha e_p\}$
Similarly, in a $p$-dimensional space, the $\ell_1$ ball is the convex hull of $\{\alpha e_1, -\alpha e_1, \alpha e_2, -\alpha e_2, \ldots, \alpha e_p, -\alpha e_p\}$
The Lipschitz constant of $\nabla f$ is easy to compute, but in this precise case we can do even better, since as we will see the line search (Variant 2) option has a closed form expression. The objective function of the line search \eqref{eq:line_search} is of the form
\begin{equation}
f(\xx_t + \gamma \dd_t) = \frac{1}{2}\|\gamma \boldsymbol{A}(\ss_t - \xx_t) + \boldsymbol{A}\xx_t - \boldsymbol{b}\|^2~,
\end{equation}
and deriving with respect to $\gamma$ we can easily verify that the following step size solves the line search problem
\begin{equation}
\gamma_t = \frac{\boldsymbol{q_t}^T (\boldsymbol{b} - \boldsymbol{A} \xx)}{\|\boldsymbol{q}_t\|^2}~,
\end{equation}
with $\boldsymbol{q}_t = \boldsymbol{A}(\boldsymbol{s}_t - \xx_t)$. Below is an example in Python of the Frank-Wolfe algorithm in this case, applied to a synthetic dataset.
This simple implementation takes around 20 seconds to solve a 10.000 $\times$ 10.0000 problem (although the emphasis of this implementation is on clarity and not speed) and produces the following output:
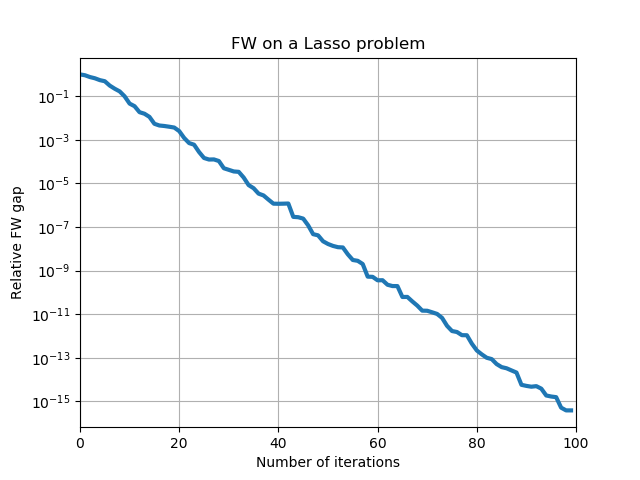 Which shows the decrease in the Frank-Wolfe gap as a function of the number of iterations. A couple of comments. First note that the gap is not monotonically decreasing. Second, although the decrease in this case seems (roughly) exponential, we can in general not guarantee an exponential (also known as linear) decrease rate for the Frank-Wolfe algorithm. This will only be the case for other variants such as the Away-steps Frank-Wolfe that we will discuss in upcoming posts.
Which shows the decrease in the Frank-Wolfe gap as a function of the number of iterations. A couple of comments. First note that the gap is not monotonically decreasing. Second, although the decrease in this case seems (roughly) exponential, we can in general not guarantee an exponential (also known as linear) decrease rate for the Frank-Wolfe algorithm. This will only be the case for other variants such as the Away-steps Frank-Wolfe that we will discuss in upcoming posts.
import numpy as np
from scipy import sparse
# .. for plotting ..
import pylab as plt
# .. to generate a synthetic dataset ..
from sklearn import datasets
n_samples, n_features = 10000, 10000
A, b = datasets.make_regression(n_samples, n_features)
def FW(alpha, max_iter=100, tol=1e-8, callback=None):
# .. initial estimate, could be any feasible point ..
x_t = sparse.dok_matrix((n_features, 1))
# .. some quantities can be precomputed ..
Atb = A.T.dot(b)
for it in range(max_iter):
# .. compute gradient. Slightly more involved than usual because ..
# .. of the use of sparse matrices ..
Ax = x_t.T.dot(A.T).ravel()
grad = (A.T.dot(Ax) - Atb)
# .. the LMO results in a vector that is zero everywhere except for ..
# .. a single index. Of this vector we only store its index and magnitude ..
idx_oracle = np.argmax(np.abs(grad))
mag_oracle = alpha * np.sign(-grad[idx_oracle])
d_t = -x_t.copy()
d_t[idx_oracle] += mag_oracle
g_t = - d_t.T.dot(grad).ravel()
if g_t <= tol:
break
q_t = A[:, idx_oracle] * mag_oracle - Ax
step_size = min(q_t.dot(b - Ax) / q_t.dot(q_t), 1.)
x_t += step_size * d_t
if callback is not None:
callback(g_t)
return x_t
# .. plot evolution of FW gap ..
trace = []
def callback(g_t):
trace.append(g_t)
sol = FW(.5 * n_features, callback=callback)
plt.plot(trace / trace[0], lw=3)
plt.yscale('log')
plt.xlabel('Number of iterations')
plt.ylabel('Relative FW gap')
plt.title('FW on a Lasso problem')
plt.xlim((0, 100))
plt.grid()
plt.show()
density = np.mean(sol.toarray().ravel() != 0)
print('Density of solution: %s%%' % (density * 100))
Convergence Theory
The Frank-Wolfe algorithm converges under very mild assumptions. As we will see, not even convexity of the objective is necessary to obtain weak convergence guarantees. As before, I will assume without explicit mention that $f$ is differentiable with $L$-Lipschitz gradient and $\mathcal{C}$ is a convex and compact set.
In this part I will present two main convergence results: one for general objectives and one for convex objectives. For simplicity I assume that the linear subproblems are solved exactly, but these proofs can easily be extended to consider approximate linear minimization oracles. These proofs can be found for example in Pedregosa, Fabian et al. "Step-size adaptivity in Projection-Free Optimization" ArXiv:1806.05123 (2018)..
The remainder of the section is structured as follows: I first introduce two key definition and technical Lemma, and finally prove the convergence results.
Definition 1: Stationary point. We will say that $\xx^\star \in \mathcal{C}$ is a stationary point if $$ \langle \nabla f(\xx^\star), \xx - \xx^\star \rangle \geq 0~\text{ for all $\xx \in \mathcal{C}$}~.$$ The intuitive meaning of this definition is that $\xx^\star$ is a stationary point if every direction in the polytope with origin at $\xx^\star$ is positively correlated with the gradient. Said otherwise, $\xx^\star$ is a stationary point if there are no feasible descent directions with origin at $\xx^\star$.
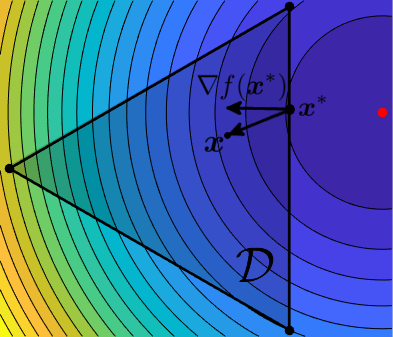
Definition 2: Frank-Wolfe gap. We denote by $g_t$ the Frank-Wolfe gap, defined as \begin{equation} g_t = \langle \nabla f(\xx_t), \xx_t - \ss_t \rangle \end{equation}
Note that by the definition of $\ss_t$ in \eqref{eq:lmo} we always have $\langle \nabla f(\xx_t), \ss_t\rangle \leq \langle \nabla f(\xx_t), \xx_t\rangle$ and so the Frank-Wolfe gap is always non-negative, and zero only at a stationary point. This makes it a good criterion to measure distance to a stationary point, and in fact convergence results for general (i.e., potentially non-convex) objectives will be given in terms of this quantity.
When $f$ is convex we also have that the FW gap verifies \begin{align}\label{eq:convexity_fw_gap} g_t &= \max_{\ss \in \mathcal{C}}\langle \nabla f(\xx_t), \xx_t - \ss\rangle \\ &\geq \langle \nabla f(\xx_t), \xx_t - \xx^\star\rangle\\ & \geq f(\xx_t) - f(\xx^\star) \end{align} where the last inequality follows from the definition of convexityA differentiable function is said to be convex if $f(\yy) \geq f(\xx) + \langle \nabla f(\xx), \yy - \xx\rangle$ for all $\xx, \yy$ in the domain. and so can be used as a function suboptimality certificate.
The next lemma relates the objective function value at two consecutive iterates and will be key to prove convergence results, both for convex and non-convex objectives. Given its usefulness in the following I will name it "Key recursive inequality".
Lemma 1: Key recursive inequality. Let $\{\xx_0, \xx_1, \ldots\}$ be the iterates produced by the Frank-Wolfe algorithm (in either variants). Then we have the following inequality, valid for any $\xi \in [0, 1]$: \begin{equation} f(\xx_{t+1}) \leq f(\xx_t) - \xi g_t + \frac{1}{2}\xi^2 L \diam(\mathcal{C})^2 \end{equation}
A consequence of the Lipschitz gradient assumption on $f$ is that we can upper bound the function $f$ at every point $\yy \in \mathcal{C}$ by the following quadratic:The Lipschitz gradient assumption in fact implies the stronger inequality $|f(\yy) - f(\xx) - \langle \nabla f(\xx), \yy-\xx\rangle|$ $\leq$ $\frac{L}{2}\|\xx - \yy\|^2$, see e.g. Lemma 1.2.3 in Nesterov's Introductory lectures on convex optimization. This implies the existance of both a quadratic upper bound and lower bound at $f(\yy)$, while in the proof we only use the upper bound. Hence, the Lipschitz assumption could be relaxed to that of having a quadratic upper bound. \begin{equation} f(\yy) \leq f(\xx) + \langle \nabla f(\xx), \yy - \xx\rangle + \frac{L}{2}\|\yy - \xx\|^2 \end{equation} We can apply this inequality, valid for any $\xx$, $\yy$ in the domain, to the special case $\xx = \xx_t$, $\yy = (1 - \gamma)\xx_{t} + \gamma \ss_t$ with $\gamma \in [0, 1]$ so that $\yy$ remains in the domain, and so we have \begin{align} f((1 - \gamma)\xx_{t} + \gamma \ss_t) &\leq f(\xx_t) + \gamma\overbrace{\langle\nabla f(\xx_t), \ss_{t} - \xx_t \rangle}^{- g_t} \nonumber\\ &\qquad+ \frac{L \gamma^2}{2}\|\ss_t - \xx_t\|^2~.\label{eq:l_smooth_xt} \end{align} We will now minimize the right hand side with respect to $\gamma \in [0, 1]$. This is a quadratic function of $\gamma$ and its minimum, which we denote $\gamma_t^\star$ is given by \begin{equation} \gamma_t^\star = \min\Big\{\frac{ g_t}{L\|\xx_t - \ss_t\|^2}, 1 \Big\}~. \end{equation} We now use the value $\gamma=\gamma_t^\star$ in the inequality \eqref{eq:l_smooth_xt} to get the following sequence of inequalities: \begin{align} &f((1 - \gamma_t^\star)\xx_{t} + \gamma_t^\star \ss_t) \\ &\leq f(\xx_t) - \gamma_t^\star g_t + \frac{L (\gamma_t^\star)^2}{2}\|\ss_t - \xx_t\|^2\\ &= f(\xx_t) + \min_{\xi \in [0, 1]}\left\{-\xi g_t + \frac{L \xi^2}{2}\|\ss_t - \xx_t\|^2\right\}\\ &\qquad \text{ (by optimality of $\gamma_t^\star$)}\nonumber\\ &\leq f(\xx_t) - \xi g_t + \frac{L \xi^2}{2}\|\ss_t - \xx_t\|^2\quad \text{ (for any $\xi \in [0, 1]$)}\nonumber\\ &\leq f(\xx_t) - \xi g_t + \frac{L \xi^2}{2}\diam(\mathcal{C})^2\label{eq:recusive_rhs_final}~. \end{align} The right hand side of the above inequality already contains the terms claimed in the Lemma. We will now bound the right hand side. For Variant 1 of the algorithm we have $f(\xx_{t+1}) = f((1 - \gamma_t^\star)\xx_{t} + \gamma_t^\star \ss_t)$, since $\gamma_t$ and $\gamma_t^\star$ coincide in this case. For Variant 2 we have $f(\xx_{t+1}) \leq f((1 - \gamma_t^\star)\xx_{t} + \gamma_t^\star \ss_t)$ since by definition of line search $f(\xx_{t+1})$ is the point that minimizes the objective value in the segment $(1 - \gamma)\xx_{t} + \gamma \ss_t$. Hence, in either case we have \begin{equation} f(\xx_{t+1}) \leq f((1 - \gamma_t^\star)\xx_{t} + \gamma_t^\star \ss_t) \end{equation} Chaining this last inequality with Eq. \eqref{eq:recusive_rhs_final} yields the claimed inequality.
The following is our first convergence rate result and is valid for objectives with $L$-Lipschitz gradient but not necessarily convex. This was first proven by Simon Lacoste-Julien:Lacoste-Julien, Simon. "Convergence rate of Frank-Wolfe for non-convex objectives." arXiv preprint arXiv:1607.00345 (2016).
Theorem 1: Convergence rate for general objectives. If $f$ is differentiable with $L$-Lipschitz gradient, then we have the following $\mathcal{O}(1/\sqrt{t})$ bound on the best Frank-Wolfe gap: \begin{equation} \min_{0 \leq i\leq t} g_i \leq \frac{\max\{2 h_0, L \diam(\mathcal{C})^2\}}{\sqrt{t+1}}~, \end{equation} where $h_0 = f(\xx_0) - \min_{\xx \in \mathcal{C}} f(\xx)$ is the initial global suboptimality.
This proof roughly follows that of Lacoste-Julien (2016), with minor differences on how the case $g_t \geq C$ is handled and with a slightly different step size rule: while I consider the step sizes of Variant 1 and 2, Lacoste-Julien considers step sizes of the form of Variant 2 and \eqref{eq:step_size_curvature} By Lemma 1 we have the following sequence of inequalities, valid for any $\xi \in [0, 1]$: \begin{align} f(\xx_{t+1})&\leq f(\xx_t) - \xi g_t + \frac{\xi^2 L }{2}\diam(\mathcal{C})^2\\ &\leq f(\xx_t) - \xi g_t + \frac{\xi^2 C }{2}~, \end{align} with $C = L \diam(\mathcal{C})^2$. We consider the value of $\xi$ that minimizes the right hand size and we obtain $\xi^* = \min\{g_t/C, 1\}$. We will now make a distinction of cases based on the value of $\xi^*$:
- If $g_t \leq C$, then $\xi^* = g_t / C$ and using this value in the previous inequality we obtain the bound \begin{equation} f(\xx_{t+1}) \leq f(\xx_t) - \frac{g_t^2}{2 C} \end{equation}
- If $g_t > C$, then $\xi^* = 1$ and we have the following sequence of inequalities \begin{align} f(\xx_{t+1}) &\leq f(\xx_t) - g_t + \frac{C}{2}\\ &\leq f(\xx_t) - \frac{g_t}{2} \quad \text{ (using $C \leq g_t$)} \end{align}
Combining both cases we have \begin{equation} f(\xx_{t+1}) \leq f(\xx_t) - \frac{g_t}{2}\min\left\{\frac{g_t}{C}, 1\right\} \end{equation} Adding the previous inequality from iterate $0$ to $t$ and rearranging we have \begin{align} -h_0 \leq f(\xx_{t+1}) - f(\xx_0) &\leq - \sum_{i=0}^t \frac{g_i}{2}\min\left\{\frac{g_i}{C}, 1\right\} \\ &\leq - (t+1) \frac{g^*_t}{2}\min\left\{\frac{g^*_t}{C}, 1\right\}~,\label{eq:ineq_optim_gt} \end{align} where $g_t^* = \min_{0\leq i\leq t} g_i$. Again, we make a distinction of cases, this time on $g_t^*$:
- If $g_t^* \leq C$, then $\min\{g^*_t/C, 1\} = g^*_t/C$ and solving for $g_t^*$ in the previous inequality we have \begin{align} g_t^* &\leq \sqrt{\frac{2 C h_0}{t+1}} \leq \frac{2 h_0 + C}{2\sqrt{t+1}} \\ & \leq \frac{\max\{2 h_0, C\}}{\sqrt{t+1}}\\ \end{align} where in the second inequality we have used Young's inequality $ab \leq \frac{a^2}{2} + \frac{b^2}{2}$ with $a = \sqrt{2 h_0}, b = \sqrt{C}$.
- If $g_t^* > C$, then $\min\{g^*_t/C, 1\} = 1$ and rearranging \eqref{eq:ineq_optim_gt} we have the following inequality with the stronger $\mathcal{O}(1/t)$ rate, which we can trivially bound by an $\mathcal{O}(1/\sqrt{t})$ bound: \begin{equation} g_t^* \leq \frac{2 h_0}{t+1} \leq \frac{2 h_0}{\sqrt{t+1}} \leq \frac{\max\{2 h_0, C\}}{\sqrt{t+1}} \end{equation}
Hence, in both cases we have \begin{equation} g_t^* \leq \frac{\max\{2 h_0, C\}}{\sqrt{t+1}}~, \end{equation} and the claimed bound follows from the definition of $g_t^*$.
Theorem 2: Convergence rate for convex objectives. If $f$ is convex and differentiable with $L$-Lipschitz gradient, then we have the following convergence rate for the function suboptimality: \begin{equation} f(\xx_t) - f(\xx^\star) \leq \frac{2 L \diam(\mathcal{C})^2}{t+1} \end{equation}
This proof uses the same proof technique as that of Nesterov Y. Complexity bounds for primal-dual methods minimizing the model of objective function (2015). A proof with similar convergence rate but different proof techniquescan be found in other papers such as Martin Jaggi's Revisiting Frank-Wolfe or Francesco Locatello's A Unified Optimization View on Generalized Matching Pursuit and Frank-Wolfe . Because of convexity we can obtain a tighter bound using the following simple inequality, mentioned earlier \eqref{eq:convexity_fw_gap}: \begin{equation}\label{eq:convex_inequality} f(\xx) - f(\xx^\star) \leq \langle\nabla f(\xx), \xx - \xx^\star\rangle~. \end{equation} Let $e_t = A_t (f(\xx_t) - f(\xx^\star))$ for a positive $A_t$ that will fix later and $C = L \diam(\mathcal{C})^2$. Then we have the following sequence of inequalities \begin{align} &e_{t+1} - e_t\nonumber\\ &\quad= A_{t+1}(f(\xx_{t+1}) - f(\xx^\star)) - A_t(f(\xx_t) - f(\xx^\star))\\ &\quad\leq A_{t+1}(f(\xx_{t}) - \xi g_t + \frac{\xi^2 C}{2} - f(\xx^\star)) - A_t(f(\xx_t) - f(\xx^\star))\\ &\quad\qquad \text{ (by Lemma 1, for any $\xi \in [0, 1]$)}\nonumber\\ &\quad\leq A_{t+1}(f(\xx_{t}) - f(\xx^\star) - \xi (f(\xx_t) - f(\xx^\star)) + \frac{\xi^2 C}{2})\nonumber\\ &\qquad - A_t(f(\xx_t) - f(\xx^\star))\qquad \text{ (by convexity \eqref{eq:convex_inequality})}\\ &\quad= ((1 - \xi) A_{t+1} - A_t) (f(\xx_{t}) - f(\xx^\star)) + A_{t+1}\frac{\xi^2 C}{2}\label{eq:convex_subopt_1}\\ \end{align} Now, choosing $A_t = \frac{t(t+1)}{2}$, $\xi = 2/(t+2)$ we have: \begin{align} (1 - \xi) A_{t+1} - A_t &= \frac{t(t+1)}{2} - \frac{t(t+1)}{2} = 0\\ A_{t+1}\frac{\xi^2}{2} &= \frac{t+1}{t+2} \leq 1~, \end{align} and so replacing with these values of $A_t$ and $\xi$ in Eq. \eqref{eq:convex_subopt_1} gives \begin{align} e_{t+1} - e_t \leq C~. \end{align} Adding this inequality from $0$ to $t-1$ and using $e_0=0$ we have for $t> 0$: \begin{equation} e_{t} \leq t C \implies f(\xx_{t}) - f(\xx^\star) \leq \frac{2 C}{t+1}~, \end{equation} where in the last implication we have divided by $t(t+1)$ and so we need $t > 0$. The claimed bound now follows from definition of $C$.
Next posts
This was the first post in a series dedicated to the Frank-Wolfe algorithm. In part 2, I strengthen Theorem 2 with primal-dual guarantees. In upcoming posts, I will discuss other guarantees (primal-dual guarantees), as well as step-size strateguies.
References
- Bach, Francis. "Duality between subgradient and conditional gradient methods." SIAM Journal on Optimization (2015).
- Jaggi M. "Revisiting Frank-Wolfe: Projection-Free Sparse Convex Optimization". ICML (2013).
- Lacoste-Julien S, Jaggi M. "On the global linear convergence of Frank-Wolfe optimization variants". In Advances in Neural Information Processing Systems (2015).
- Lacoste-Julien, Simon. "Convergence rate of Frank-Wolfe for non-convex objectives." arXiv preprint arXiv:1607.00345 (2016).
- Locatello, F., Khanna, R., Tschannen, M. and Jaggi, M. "A Unified Optimization View on Generalized Matching Pursuit and Frank-Wolfe". , Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (2017)
- Nesterov, Yu. "Complexity bounds for primal-dual methods minimizing the model of objective function." Mathematical Programming (2017).
- Pedregosa, Fabian and Askari, Armin and Negiar, Geoffrey and Jaggi, Martin (2018) "Step-Size Adaptivity in Projection-Free Optimization". arXiv:1806.05123
- Historial perspective on the Frank-Wolfe algorithm. Marguerite Frank gives a beautiful historical perspective on the algorithm at the 2013 NIPS workshop "Greedy Algorithms, Frank-Wolfe and Friends"