Courtney Paquette, Jeffrey Pennington, Tom Trogdon and I gave a tutorial at the ICML 2021 conference on the applications of random matrix theory to machine learning.
All course materials can be found in the website https://random-matrix-learning.github.io/.
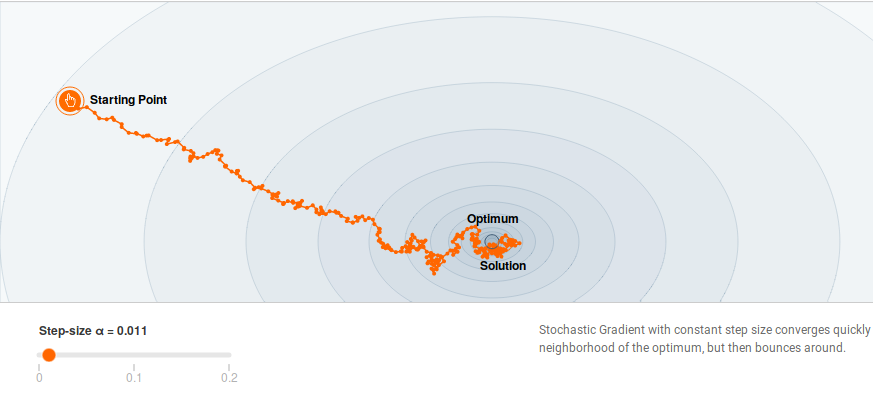
"A birds-eye view of optimization algorithms". Material for a 1.5h introduction to optimization algorithms given in 2018.

 Technological advances in data gathering and storage have led to a rapid proliferation of large amounts of data in diverse areas such as climate studies, cosmology, medicine, Web data processing, and engineering. Making sense of this data deluge requires a set of skills which have become fundamental in any major corporation and any almost any scientific discipline.
Technological advances in data gathering and storage have led to a rapid proliferation of large amounts of data in diverse areas such as climate studies, cosmology, medicine, Web data processing, and engineering. Making sense of this data deluge requires a set of skills which have become fundamental in any major corporation and any almost any scientific discipline.
Instructors: Fabian Pedregosa, Laurent El Ghaoui, Bowen Yin Wang (Teaching Assistant).
![]() How can we tune the parameters of a logistic regression model using terabytes of data, when most machines nowadays only have a few dozens or at most a few hundreds of gigabytes of RAM?
How can we tune the parameters of a logistic regression model using terabytes of data, when most machines nowadays only have a few dozens or at most a few hundreds of gigabytes of RAM?
The goal of this course will be to familiarize students with algorithmic tools that are now crucial to run machine learning algorithms at scale: namely stochastic, incremental, distributed and asynchronous optimization. We will cover these tools both in theory, to study their convergence properties, and in practice, through code exercises.
Master M2: Mathématiques, Apprentissage et Sciences Humaines (MASH)

The goal of this course is to develop experience in machine learning through real world data science challenges.